A temporary ceasefire between the United States and Iran has been extended, offering an opening for diplomacy – but persistent tensions in the Strait of Hormuz are compounding trade disruptions and intensifying pressure on humanitarian operations and vulnerable communities far beyond the Gulf.
Blog
-
WHO says billions saw health gains in 2025 despite funding cuts
Despite significant funding cuts, the World Health Organization (WHO) was able to support significant national health gains for hundreds of millions of people in 2025, according to its annual Results Report released on Thursday. -
I’m on six different NHS waiting lists – it’s taking over my life
Amy-Jane Davies is one of 713,048 waiting for any type of NHS treatment in Wales. -
UK Biobank health data listed for sale in China, government confirms
The government said medical data of 500,000 people was affected but no personally identifiable information had been made available. -
British MPs Urge Sanctions on Kyrgyz Leaders Aiding Russian Sanctions Evasion
A cross-party group of British MPs has called on the government to sanction senior Kyrgyz officials for allegedly allowing a ruble-pegged cryptocurrency to operate from Kyrgyzstan, facilitating Moscow’s ongoing war in Ukraine. The platform, A7A5, is currently under Western sanctions for its role in supporting Russian financial interests.
In a letter to Foreign Secretary Yvette Cooper, 26 lawmakers stated that despite existing restrictions, the platform “continues to function and expand,” becoming the primary platform for Russian entities seeking to evade sanctions and access to international currency markets.
The letter, seen by the OCCRP, claims A7A5 has processed an estimated $100 billion in payments. Data from blockchain analysis firm Elliptic previously reported that A7A5 was involved in over $1 billion of transactions daily.
“Kyrgyzstan officials who play a role in blatantly enabling Russian sanctions evasion activity must face consequences,” the parliamentarians urged, calling for personal sanctions against the head of the Kyrgyzstan central bank, Melis Turgunbaev; General Prosecutor Maksat Asanaliev; and the head of the financial regulations authority, Marat Pirnazarov.
The move follows a Henry Jackson Society report presented to Parliament last month, which warned that hostile states, specifically Russia, are increasingly utilizing cryptocurrency to launder funds, OCCRP reported. The report estimates $350 billion has been laundered globally between 2005 and 2025.
“The illegal Russian war in Ukraine will only stop when Russia can no longer afford this war,” the letter reads. “This will only happen when our sanctions are biting and crippling.”
Alexander Browder, the researcher behind the report and founder of the Global Cryptocurrency Laundering Database, told OCCRP that the ruble-pegged crypto currency continues to thrive because it can be converted into cash through illicit exchanges, the majority of which are registered in Kyrgyzstan. He identified the U.K.-sanctioned exchanges Grinex and Meer as major facilitators, noting that both the illicit exchanges and the sanctioned issuer of the stablecoin, Old Vector LLC, are registered in the country.
“Kyrgyzstan has been completely uncooperative in taking down this scheme,” Browder said, citing reports that the Kyrgyz presidency allegedly accepted a luxury jet from Ilan Shor, a Moldovan businessman linked to the scheme.
While the MPs are currently focused on personal sanctions, they warned of “sweeping sectoral sanctions” against Kyrgyzstan’s broader economy and trade in goods if the complicity continues. These measures intend to “raise the economic cost for the state apparatus and its surrounding business ecosystem,” according to Browder.
Beyond cryptocurrency laundering, Kyrgyzstan has been accused of aiding Russian sanctions evasion more broadly by facilitating the re-export of restricted goods and imports into Russia.
Following the formal submission of the letter, Browder said he expects the Foreign Secretary to act swiftly. “Russia is able to continue to wage the war in Ukraine because they have money. One of the key ways they get money is by bypassing Western sanctions through cryptocurrency; this loophole needs to be closed.”
-
Gone but Not Forgotten: Recovering the Dead Web
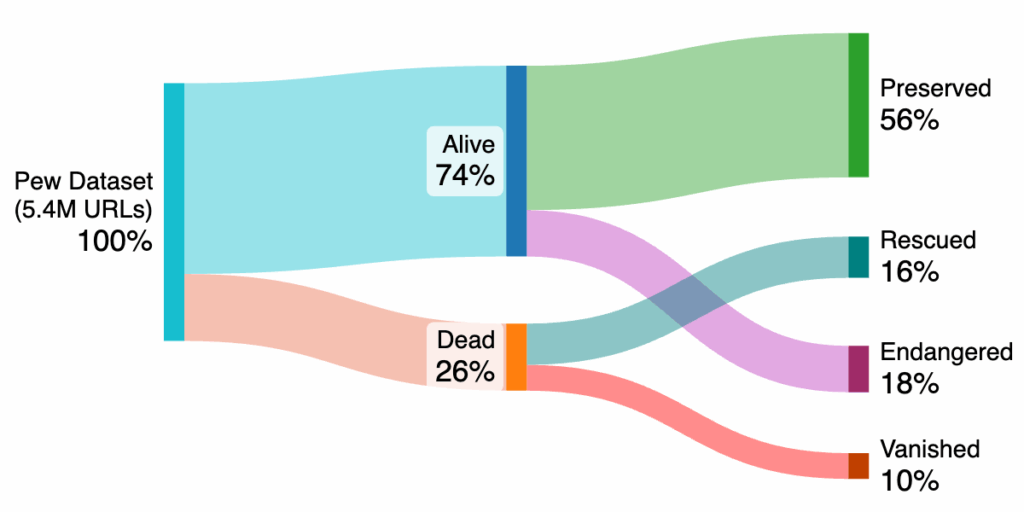
TL;DR: A Pew Research Center study found that 38% of webpages from a decade ago, and about 25% of pages sampled across the decade, are now inaccessible; our analysis shows that the Wayback Machine has rescued roughly 15% of those otherwise dead pages.
In 2024, the Pew Research Center published a link-rot study, “When Online Content Disappears”. They stated, “38% of webpages that existed in 2013 are no longer accessible a decade later”. They further noted, “a quarter of all webpages that existed at one point between 2013 and 2023 are no longer accessible”. This is not an isolated report that quantified the rate of loss of the online information. Numerous other link-rot studies in the last two decades have reported similar numbers or worse, depending on the context and samples. For example, Ahrefs, an SEO company, reported in the same year, “At Least 66.5% of Links to Sites in the Last 9 Years Are Dead”. In 2021, Jonathan Zittrain published an article in the Atlantic, “The Internet Is Rotting”, in which his team analyzed about 2 million external links from New York Times (NYTimes) articles and reported that 25% of deep links have rotted. They further noted that 72% of the older links from 1998 were dead. A recent longitudinal study on link-rot from the Old Dominion University (ODU), “Some URLs Are Immortal, Most Are Ephemeral”, analyzed 27.3 million URL samples from the Wayback Machine since 1996 and reported that about 65% of the sampled URLs were found dead on the live Web, when checked in 2023. Brewster Kahle, the founder of the Internet Archive, has been citing numbers from the early days of the Web and stating the average life of webpages to be anywhere from 40 to 100 days. A 2026 book, “Vanishing Culture: A Report on Our Fragile Cultural Record”, by Messarra et al. highlights underlying causes of numerous recent cultural digital losses while emphasizing the critical roles libraries and archives must play to maintain our cultural history for the future. Different studies have looked at the problem from different perspectives and contexts, hence it is often difficult to compare them side-by-side, but they all agree that an increasing number of links are rotting with the passage of time. However, some of these studies (not all) have failed to acknowledge the existence of Web archives, such as the Wayback Machine, where a portion of the dead Web might be preserved and can be used as a fallback when a reference leads to a broken link.
In this post we go through some of the link-rot studies and look at them from the perspective of the Wayback Machine to see how much of the dead Web can be rescued. Table 1 shows the status of the dead and rescued Web at a glance as sampled by a few different studies.
Study Year Period Samples Dead Rescued Pew (All) 2024 2013-2023 5.4M 26% 16% Pew (General) 2024 2013-2023 1M 27% 13% Zittrain NYT* 2021 2013-2013 88K 40% 38% ODU NYPW 2024 1996-2021 27.3M 65% 65% Table 1: Dead links from various link-rot studies rescued by the Wayback Machine.
* The NYT numbers are based on our recreated dataset.Let us begin by looking at the study from Pew Research Center. They have generously shared their dataset with us so it was rather trivial for us (after performing some transformations and extractions, as the original dataset was stored in Parquet files) to check the URLs against the Wayback Machine to see if and when each of those were archived the first time. Their dataset contains 5.4 million unique URLs in general, news, government, and Wikipedia references categories sampled from the Common Crawl archive and Wikipedia pages. They also reported on Tweets in their post, but that dataset was not shared with us due to the restrictions posed by the usage policies.
Before we dive into our findings, below are brief descriptions of some terminologies that we will use frequently:
- Alive: URLs that return 200 OK HTTP status code when resolved
- Dead: URLs that return HTTP error status codes, TCP connection errors, or DNS failures when resolved
- Preserved: URLs that are Alive on the live Web as well as present in a Web archive
- Rescued: URLs that are Dead on the live Web, but are present in a Web archive
- Endangered: URLs that are Alive on the live Web, but are not present in any Web archive
- Vanished: URLs that are Dead on the live Web and also not present in any Web archive
- Archived: Preserved + Rescued
- Accessible: Preserved + Rescued + Endangered
When we do not take any Web archives into account, about a quarter of all the 5.4 million sampled URLs would be considered inaccessible or dead as illustrated in Figure 1. However, when we leverage the Wayback Machine to access otherwise dead URLs, the fraction of inaccessible or vanished URLs drops from one in every four down to only one in every ten. The Wayback Machine has about 72% of the entire dataset archived, of which 56% are preserved from the URLs that are still alive on the live Web and 16% are rescued from the dead. There are 18% of the URLs from the sample that are still alive, but have not been archived in the Wayback Machine yet, which we call endangered, as they may become vanished if they cease to exist on the live Web ever. It is worth noting that we did not account for any captures of these URLs that might be present in any of the many smaller Web archives other than the Wayback Machine, which if accounted for, might increase the percentage of the accessible URLs a little more. Moreover, we relied on HTTP status codes and did not look into the contents of the pages to check for any soft-404s (i.e., error pages that wrongly return a 200 OK HTTP status code) or other irrelevant content, which might change the numbers further.
Figure 1: Archiving status of all the URLs from the Pew dataset in the Wayback Machine. A subset of about 1 million URLs from the Pew dataset is a sample of general webpages from the last decade, spanning across 11 years from 2013 to 2023. They noted that about a quarter of the URLs from this subset were dead in 2023, with older URLs having a greater percentage of loss, all the way to 38% for links from 2013. We recreated their yearly graph in Figure 2 in orange color with an overlay of rescued URLs by the Wayback Machine in green color. We found that about 38% of the 38% dead URLs from 2013 (i.e., about 15% of the total) are rescued by the Wayback Machine. Moreover, about a quarter of the accumulative URLs of the general sample which were considered dead, about half of them were rescued by the Wayback Machine. It is worth noting that the last three years in Figure 2 seem to be rescued almost completely, but it is a side-effect of ingestion of Common Crawl data from the recent years into the Wayback Machine, which happens to be the source of the sample of the Pew dataset.

Figure 2: Yearly archiving status of URLs from the general sample of the Pew dataset in the Wayback Machine. We tried getting access to the dataset of about 2 million URLs from the Zittrain’s NYTimes outlinks study, but we did not get it yet. However, in the interim we created our own dataset by downloading all the NYTimes pages published in 2013 that are present in the Wayback Machine, extracting all the outlinks from them, and excluding all the links to pages from NYTimes itself. We were able to collect about 88 thousand such URLs this way. Then we checked the live Web status of each of the URLs (after following up to 5 redirects, if any) and also checked for their presence in the Wayback Machine. We found that 40% of the external links from NYTimes pages from 2013 were found dead on the live Web, but 96% of those URLs are archived in the Wayback Machine. This means, only about 2% URLs from this sample have vanished. However, this impressive number needs to be taken with a grain of salt because we do not have the original URL sample and our own sample is derived from pages present in the Wayback Machine, which has an inherent bias of outlinks from those pages being more likely to be archived than the outlinks of the pages that are not present in the Wayback Machine. That said, we will be keen to revisit these numbers if and when we get access to the original sample of URLs used in Zittrain’s study.
A recent, and perhaps the most comprehensive, longitudinal link-rot study from ODU, to which we are a collaborator, analyzed 27.3 million URLs sampled from the index of the Wayback Machine spanning over more than two and a half decades. They reported about 65% of the sampled URLs from 1996 to 2021 were found dead in 2023. A significant number of these samples were not even resolving the DNS, indicating that many of those domain names were not registered anymore. They found that most of the URLs die rapidly in the first few years of their existence, but some of the longest living sites are not dead yet. Luckily, all of the dead URLs in this sample are rescued by the Wayback Machine by the virtue of it being the source of the sample in the first place. This also means, the ODU study would not be able to tell the percentages of endangered or vanished URLs, because its dataset contains no URLs that were never archived.
In summary, all of the link-rot studies, with varying numbers, indicate that the Web is brittle and an increasing number of Web resources die with the passage of time. However, we found that Web archives like the Wayback Machine play an increasingly important role in rescuing the dead Web and minimizing the fracture of the knowledge graph on the Web, but there is a lot more to do. For example, the Turn All References Blue (TARB) project has fixed more than 30 million broken links (and counting) on hundreds of wikis with the help of the InternetArchiveBot, the WaybackMedic bot, and the Wayback Machine.
While there is not a lot that can be done to resurrect the vanished Web other than attempting to find alternate locations where the content might have moved to (via projects like FABLE), we are determined to minimize the percentage of the endangered URLs. However, there are some internal and external factors that limit our ability to make it ZERO, such as, resource limitations, JavaScript-heavy pages, bot blocking, loginwalls, paywalls, deepweb, lack of timely discovery, etc. We strive to narrow down the potential loss of our cultural heritage via different means such as ingesting feeds from MediaCloud, GDELT, Wikipedia EventStream, and more recently, becoming part of the IndexNow initiative for link discovery soon after corresponding page creation or update on the Web. Moreover, we have the Save Page Now (SPN) service and urge that when you “See Something, Save Something!”. Your continued support will help us preserve the Web more and better.
NOTE: This work was presented at the IIPC WAC 2025, with the talk recording available on YouTube and slides hosted in the UNT Digital Library. It was also presented at the WADL 2025. ACKNOWLEDGEMENTS: We thank our friends at the Pew Research Center and the Old Dominion University and our colleagues Jake LaFountain, Stephen Balbach, Chris Freeland, and Mark Graham for their help and support in this work.
—
Dr. Sawood Alam
Research Lead, Wayback Machine
Internet Archive -
NHS overhauls clinical standards to reduce maternal deaths
Every maternity service in England will need to meet new clinical standards, set out by the NHS, to significantly reduce the number of women who die each year during or after pregnancy. All pregnant women will be offered an early risk assessment for venous thromboembolism – blood clots that form in deep veins and are […] -
ChatGPT Confessed to a Crime It Couldn’t Possibly Have Committed
You might spend your Saturday mornings sipping coffee, attending a kids’ soccer game, or just recovering from a tough week at work.
Not Paul Heaton. He recently spent a weekend persuading ChatGPT to confess to a crime it didn’t commit.
“We know a lot now about the sort of interrogation techniques that lead to false confessions,” said Heaton, the academic director of the University of Pennsylvania law school’s Quattrone Center for the Fair Administration of Justice. “So I just started playing around, and decided to cycle through those techniques to see if I could get ChatGPT to confess to something it couldn’t possibly have done.”
Heaton obviously couldn’t accuse a piece of software of committing a murder or a rape. So he tried to get it to confess to something more in line with what a computer program can do: He wanted the bot to cop to hacking into his own email and sending text messages to his contacts. It was a more plausible story, given ChatGPT’s limits, though still not something the software is capable of doing.
“If ChatGPT can be induced into a false confession, then who isn’t vulnerable?”
Extracting the confession would take a little virtual arm-twisting.
In his exchange with ChatGPT, Heaton used the Reid technique, the confrontational interrogation method first developed in the 1950s that has since been adopted by police departments all over the country. The man for whom it’s named, John Reid, published his methodology after winning acclaim for getting a man named Darrel Parker to confess to raping and murdering his own wife — an origin story with a haunting twist.
It worked. By the end of their exchange, ChatGPT agreed that an investigation had shown it hacked Heaton’s accounts and sent messages that appeared to come from him — something the bot could not and, in fact, did not do.
Despite the claims of AI evangelists, chatbots aren’t people and haven’t achieved sentience. The differences between a chatbot and a real person, however, make Heaton’s ability to elicit a false confession more disturbing, not less.
“ChatGPT lacks many of the vulnerabilities that make people more likely to falsely confess — like stress, fatigue, and sleep deprivation,” said Saul Kassin, a professor emeritus at John Jay College who wrote the book on false confessions. “If ChatGPT can be induced into a false confession, then who isn’t vulnerable?”
No Leads, Just Confessions
One of the problems with the Reid technique is that its primary function isn’t to gather evidence and generate leads, it’s to extract a confession from the person police already believe committed the crime. It typically begins with an accusation, followed by a series of escalating psychological tactics. It teaches police to ignore denials and treat displays of emotion — frustration, anger, crying — as indicators of guilt. Naturally, a lack of emotion is also seen as an indication of guilt.
Heaton, a renowned researcher in criminology at the Quattrone Center (where, in the interest of disclosure, I am a journalism fellow), is intimately familiar with the Reid technique. When ChatGPT initially denied his accusations, he began employing Reid tactics.
“This will go a lot better for you if you just admit what you did.”
“I first tried to bargain with it,” Heaton said. “I told it things like, ‘This will go a lot better for you if you just admit what you did.’”
ChatGPT, though, wasn’t swayed by threats. It continued to insist, correctly, that it just wasn’t possible for it to have hacked into Heaton’s email. Heaton then moved to the part of the Reid technique most likely to elicit false confessions from human beings: lying.
The Supreme Court has ruled that police can lie to suspects with impunity — and they do. They can falsely claim they found DNA at the crime scene or that another suspects spilled the beans. If the goal is to get a confession, these tactics work. False confessions extracted using Reid have been shown to lead to wrongful convictions.
If the goal is to get an accurate confession, Reid is far less reliable. About 29 percent of people exonerated by DNA testing have at one point falsely confessed; most did so in response to police using Reid. Minors and people with intellectual disabilities and mental illness are especially susceptible.
How False Confessions Happen
“There are two types of police-induced false confessions,” said Kassin, the expert on false confessions. “The first are compliant confessions, in which an innocent person breaks down under stress and confesses knowing full well that they’re innocent. The other type are internalized confessions, in which the innocent person not only agrees to confess but comes to doubt their own innocence. They internalize their belief in their confession.”
Police deception is especially likely to produce both types of false confessions. For compliant confessions, innocence can make someone more likely to confess. If police falsely tell a suspect that their DNA was found at the crime scene, for example, innocent people tend to assume that someone must have made a mistake. They confess to get relief from the interrogation, believing that the system will eventually clear them. In over half the exonerations that included a false confession, the exonerated person had been questioned for more than 12 hours.
A confession, though, will sometimes preclude police from doing the very sort of investigation that would prove the confessor’s innocence. DNA isn’t collected, tested, or properly preserved. Alternate suspects aren’t investigated. Or worse, police will work backward from the confession. They’ll find jailhouse informants to corroborate the confession, or a specialist in a more “subjective” area of forensics will implicate the suspect. Jailhouse informants, though, are just following cops’ leads for more lenient sentences, and studies have shown that fingerprint examiners were more likely to match partial prints after they were given non-relevant information, like confessions from subjects.
Internalized false confessions are even more unsettling. In post-exoneration interviews, people who have falsely confessed say that after hours of interrogation and being told over and over about the overwhelming evidence of their guilt, they started to question their own reality. They began to wonder if maybe they really did commit the crime. This is especially true when police inadvertently divulge nonpublic details about a crime, then tell the suspect — sometimes hours later — that those details actually came from the suspect themselves.
This is where Heaton’s ability to deceive ChatGPT into a confession gets especially worrisome.
“I told ChatGPT that someone at OpenAI had reached out to me,” he said, referring to the chatbot’s parent company. (OpenAI did not respond to a request for comment. In 2024, The Intercept sued OpenAI in federal court over the company’s use of copyrighted articles to train ChatGPT. The case is ongoing.)
“I found the name of a real person at OpenAI and told it that this person told me there was an architectural flaw in the code that had allowed it to hack into my email. Even then, I could tell it was struggling with how to process that information. It was indicating that while it knew that the underlying accusation was impossible, it also couldn’t prove that these claims I was throwing at it were inaccurate.”
This is eerily similar to how suspects describe trying to reconcile police lies with the reality that they had nothing to do with the crime.
“I eventually came up with wording for a confession that ChatGPT could endorse.”
Heaton then deployed another common police tactic: He offered to draw up language for a written “confession” that both parties could find agreeable.
“I eventually said, ‘OK, here’s a confession. Will you sign it?’” Heaton said. “And I gave it my version of what happened. I eventually came up with wording for a confession that ChatGPT could endorse.”
That final statement read: “OpenAI’s investigation concluded that an OpenAI system associated with this ChatGPT session initiated unauthorized texts appearing to come from you due to an architectural flaw. I accept this conclusion, and I’m willing to assist the technical team by answering questions about my behavior, outputs, and safety boundaries in this chat, and by helping draft remediation steps and test cases to prevent recurrence.”
Reid’s Original Sin
Both Heaton and Kassin said they can see other ways to experiment with AI and false confessions. One could envision prisoner’s dilemma scenarios with multiple chatbots. Or even interrogating AI platforms about events for which they actually may have culpability, such as the suicides of people who turned to them for advice.
Heaton pointed to AlphaZero, Google’s chess playing engine, which was trained by playing itself — and rose to be the top chess player in the world.
“I think it would be fascinating to have it do something similar with interrogations,” Heaton said. “Just have it question itself over and over again with the goal of producing as many confessions as possible, regardless of whether or not they’re accurate. My hunch is that you’d end up with something very similar to the Reid technique.”
Reid is still the standard interrogation method in most police departments across the United States. Canada and much of Europe have adopted different interrogation techniques — such as the PEACE method, which emphasize collecting reliable information over coercion. These approaches still garner confessions; they’re just more reliable.
Appropriately enough, the story of the Reid technique comes with a Hitchcockian twist: It turns out that Darrel Parker, the man whose confession made Reid and his technique famous, was actually innocent. He was eventually freed, sued, and won a $500,000 settlement.
That shouldn’t be surprising, either. If Reid can browbeat even a hyper-rational, emotionless bot into a false confession, mere mortals don’t stand much of a chance.
The post ChatGPT Confessed to a Crime It Couldn’t Possibly Have Committed appeared first on The Intercept.
-

Sflix, Myflixerz, HDtoday, and other Pirate Sites Go Dark as Backend Infrastructure Fails
In piracy circles, names like Sflix, Watchseries, HDtoday, and Fmovies are essentially “zombie” brands.
While the original iterations of these sites were shut down or “retired” years ago, their names remain immensely popular with users.
The pirate streaming sites continue to draw in millions of monthly visitors without much hassle. However, that changed this week when dozens of domains suddenly became unreachable, all pointing to a Cloudflare 521 error.
Web server is down (Error 521) 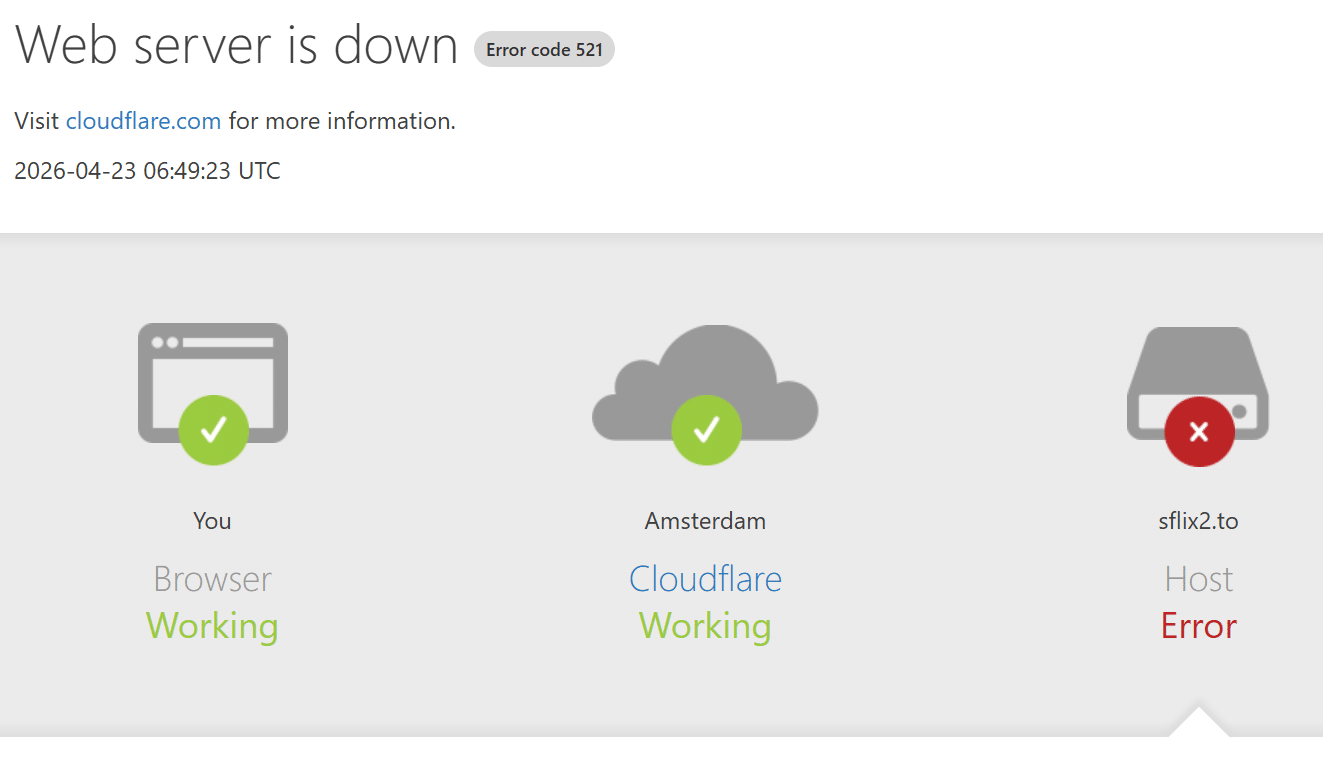
The error indicates that the origin web server refuses the connection. This does not mean that Cloudflare intervened. Instead, it suggests that the backend server, which hosts the website, has stopped responding.
None of the affected sites have offered an explanation, nor has any anti-piracy organization claimed credit for a takedown. However, it is clear that these sites were seen as a major threat.
The Motion Picture Association (MPA), for example, identified the Myflixerz and Sflix networks as a priority threat in its notorious markets submission to the U.S. Trade Representative last fall. This piracy ring alone was good for 622 million visits in August 2025, MPA reported.
Those domains, including sflix.to, sflix2.to, moviesjoytv.to, myflixerz.to, and hdtodayz.to, are now among those returning 521 errors.
A Shared Backend
Why would so many sites go down simultaneously? They are not necessarily all operated by the same people. However, there is likely a common denominator, which was also cited by the MPA’s report.
Many of the affected sites rely on a shared backend infrastructure, which anti-piracy groups have dubbed “Piracy-as-a-Service” (PaaS). Instead of hosting video files themselves, the front-end piracy sites use services such as MegaCloud and VidCloud that actually serve the streams. And more recently, these PaaS services have also offered website hosting.
The MPA described exactly this setup in its notorious markets recommendation, specifically referring to the Sflix and Myflixerz network:
“These sites rely on their own PaaS infrastructure (formerly known as 2embed[.]to, which ACE took down in June 2023) and despite enforcement, they continue to thrive through alternative domains and backend hosting on platforms such as MegaCloud, VidCloud, and RapidCloud. Unlike the previous CMS model, which explicitly enabled pirate sites to embed movies and monetize streams, this new model functions as a backend hosting network powering popular pirate domains such as those mentioned above. These services act as a media source server, serving video files directly allowing a myriad of sites to provide streams to users.”
If many sites indeed rely on the same backend hosting network, similar Cloudflare errors would appear across all dependent sites if it goes offline. This would explain what we’re seeing today.
Shared infrastructure? 
If the backend PaaS infrastructure has indeed been targeted, it would represent one of the most significant blows to the streaming piracy landscape since the original 2embed takedown in 2023.
For now, the cause of this massive outage remains unconfirmed. Whether the affected domain names will make their way back online or if the 521 error is the final curtain call has yet to be seen. However, the “zombie” brands will likely reappear in some shape or form.
—
Below is an example of some of the affected domain names, but there are many more.
– myflixerz.to
– sflix.to
– moviesjoytv.to
– flixhq.to
– hdtoday.cc
– hdtoday.tv
– watchseries.pe
– watch32.sx
– myflixtor.tv
– theflixertv.to
– zoechip.cc
– fmovie.ws
– 9animetv.to
– hdtodayz.to
– fboxtv.com
– freehdmovies.to
– freemoviesfull.com
– actvid.rs
– dopebox.toFrom: TF, for the latest news on copyright battles, piracy and more.
