The Diary of Anne Frank, written by a young girl hiding from the Nazis in Amsterdam during World War II, is one of the best-known literary works in history.
While the diary’s importance is widely agreed upon, the accessibility of its digital likeness remains at the center of a modern-day copyright battle.
These copyrights are controlled by the Swiss-based Anne Frank Fonds, which was the sole heir of Anne’s father, Otto Frank. The Fonds states that many print versions of the diary remain protected for decades, and even the manuscripts are not freely available everywhere.
In the Netherlands, for example, certain sections of the manuscripts remain protected by copyright until 2037, even though they have entered the public domain in neighboring countries like Belgium.
To navigate these conflicting laws, the Dutch Anne Frank Stichting published a scholarly edition online using “state-of-the-art” geo-blocking to prevent Dutch residents from accessing the site. Visitors from the Netherlands and other countries where the work is protected are met with a clear message, informing them about these access restrictions.
“The scholarly edition of the Anne Frank manuscripts cannot be made available in all countries, due to copyright considerations,” is the message disallowed visitors get to see.
Despite these blocking measures, the Swiss-based Anne Frank Fonds was not pleased. The Fonds essentially argued that if a block isn’t 100% bypass-proof, the content shouldn’t be online at all.
The Dutch lower court dismissed this argument, stating the defendants had taken reasonable measures to prevent access from the Netherlands. The Fonds appealed, without result, and the case is now before the Dutch Supreme Court, which referred several questions to the EU’s top court (CJEU) to decide the fate of VPN neutrality and the sufficiency of geo-blocking.
Court Adviser Backs VPN Neutrality
In an opinion published this month, Advocate General Rantos of the Court of Justice of the European Union (CJEU) sides with common sense, concluding that geo-blocking is a sufficient measure to protect against unauthorized access.
The opinion concludes that digital copyright protections can always be broken or bypassed. That by itself should not automatically mean that the publisher is liable, especially if ‘state-of-the-art’ geo-blocking measures are in place, as the Anne Frank Stichting argued.
“Liability would only arise if the technical measures were found to be deliberately ineffective so that they could be easily circumvented,” the opinion reads.
Equally important, Rantos concludes that a VPN provider isn’t liable for the unlawful actions of users who use their service to bypass geographical restrictions.
“The mere fact that those or similar services may be used for [unlawful] purposes is not sufficient to establish that the service providers themselves communicate the protected work to the public,” the Advocate General writes.
“It would be different if those service providers actively encouraged the unlawful use of their services. In that case, the service providers could be regarded as playing an essential role in making the works in question available.”
From the opinion
In other words, the opinion concludes that VPNs are neutral services and that they can only be held liable if they actively encourage copyright infringement or other wrongdoing.
What’s Next?
The opinion is not binding for the CJEU, which is expected to issue its final ruling later this year. This final ruling will be key for the digital future of the Anne Frank Diary, as well as all other geo-blocked content on the Internet.
If the court agrees with the opinion of Advocate General Rantos, the status quo will remain. However, if geo-blocking were somehow not to be sufficient, this would impact hundreds of popular sites and services, including all popular video streaming platforms.
Even worse, if VPNs were to be held liable for the actions of users without the providers’ awareness, that would create some significant backlash.
—
A copy of the opinion of Advocate General Athanasios Rantos, delivered on 15 January, is available here (pdf).
From: TF, for the latest news on copyright battles, piracy and more.
When the official White House X account posted an image depicting activist Nekima Levy Armstrong in tears during her arrest, there were telltale signs that the image had been altered.
Less than an hour before, Homeland Security Secretary Kristi Noem had posted a photo of the exact same scene, but in Noem’s version Levy Armstrong appeared composed, not crying in the least.
Seeking to determine if the White House version of the photo had been altered using artificial intelligence tools, we turned to Google’s SynthID — a detection mechanism that Google claims is able to discern whether an image or video was generated using Google’s own AI. We followed Google’s instructions and used its AI chatbot, Gemini, to see if the image contained SynthID forensic markers.
After posting the article, however, subsequent attempts to use Gemini to authenticate the image with SynthID produced different outcomes.
In our second test, Gemini concluded that the image of Levy Armstrong crying was actually authentic. (The White House doesn’t even dispute that the image was doctored. In response to questions about its X post, a spokesperson said, “The memes will continue.”)
In our third test, SynthID determined that the image was not made with Google’s AI, directly contradicting its first response.
At a time when AI-manipulated photos and videos are growing inescapable, these inconsistent responses raise serious questions about SynthID’s reliability to tell fact from fiction.
A screenshot of the initial response from Gemini, Google’s AI chatbot, stating that the crying image contained forensic markers indicating the image had been manipulated with Google’s generative AI tools, taken on Jan. 22, 2026.Screenshot: The Intercept
Initial SynthID Results
Google describes SynthID as a digital watermarking system. It embeds invisible markers into AI-generated images, audio, text or video created using Google’s tools, which it can then detect — proving whether a piece of online content is authentic.
“The watermarks are embedded across Google’s generative AI consumer products, and are imperceptible to humans — but can be detected by SynthID’s technology,” says a page on the site for DeepMind, Google’s AI division.
Google presents SynthID as having what in the realm of digital watermarking is known as “robustness” — it claims to be able to detect the watermarks even if an image undergoes modifications, such as cropping or compression. Therefore, an image manipulated with Google’s AI should contain detectable watermarks even if it has been saved multiple times or posted on social media.
Google steers those who want to use SynthID toward its Gemini AI chatbot, which they can prompt with questions about the authenticity of digital content.
“Want to check if an image or video was generated, or edited, by Google AI? Ask Gemini,” the SynthID landing page says.
We decided to do just that.
We saved the image file that the official White House account posted on X, bearing the filename G_R3H10WcAATYht.jfif, and uploaded it to Gemini. We asked whether SynthID detected the image had been generated with Google’s AI.
To test SynthID’s claims of robustness, we also uploaded a further cropped and re-encoded image, which we named imgtest2.jpg.
Finally, we uploaded a copy of the photo where Levy Armstrong was not crying, as previously posted by Noem. (In the above screenshot, Gemini refers to Noem’s photo as signal-2026-01-22-122805_002.jpeg because we downloaded it from the Signal messaging app).
“I’ve analyzed the images you provided,” wrote Gemini. “Based on the results from SynthID, all or part of the first two images were likely generated or modified with Google AI.”
“Technical markers within the files imgtest2.jpg and G_R3H10WcAATYht.jfif indicate the use of Google’s generative AI tools to alter the subject’s appearance,” the bot wrote. It also identified the version of the image posted by Noem as appearing to “be the original photograph.”
With confirmation from Google that its SynthID system had detected hidden forensic watermarks in the image, we reported in our story that the White House had posted an image that had been doctored with Google’s AI.
This wasn’t the only evidence the White House image wasn’t real; Levy Armstrong’s attorney told us that he was at the scene during the arrest and that she was not at all crying. The White House also openly described the image as a meme.
A Striking Reversal
A few hours after our story published, Google told us that they “don’t think we have an official comment to add.” A few minutes after that, a spokesperson for the company got back to us and said they could not replicate the result we got. They asked us for the exact files we uploaded. We provided them.
The Google spokesperson then asked, “Were you able to replicate it again just now?”
We ran the analysis again, asking Gemini to see if SynthID detected the image had been manipulated with AI. This time, Gemini failed to reference SynthID at all — despite the fact we followed Google’s instructions and explicitly asked the chatbot to use the detection tool by name. Gemini now claimed that the White House image was instead “an authentic photograph.”
It was a striking reversal considering Gemini previously said that the image contained technical markers indicating the use of Google’s generative AI. Gemini also said, “This version shows her looking stoic as she is being escorted by a federal agent” — despite our question addressing the version of the image depicting Levy Armstrong in tears.
A screenshot of Gemini’s second response, this time stating that the same image it previously said SynthID detected as being doctored with AI, was in fact an authentic photograph, taken on Jan. 22, 2026.Screenshot: The Intercept
Less than an hour later, we ran the analysis one more time, prompting Gemini to yet again use SynthID to check whether the image had been manipulated with Google’s AI. Unlike the second attempt, Gemini invoked SynthID as instructed. This time, however, it said, “Based on an analysis using SynthID, this image was not made with Google AI, though the tool cannot determine if other AI products were used.”
A screenshot of Gemini’s third response, this time stating that SynthID had determined that the image was not made with Google AI, after all, despite earlier saying SynthID found that it had been generated with Google’s AI, taken on Jan. 22, 2026.Screenshot: The Intercept
Google did not answer repeated questions about this discrepancy. In response to inquiries, the spokesperson continued to ask us to share the specific phrasing of the prompt that resulted in Gemini recognizing a SynthID marker in the White House image.
We didn’t store that language, but told Google it was a straightforward prompt asking Gemini to check whether SynthID detected the image as being generated with Google’s AI. We provided Google with information about our prompt and the files we used so the company could check its records of our queries in its Gemini and SynthID logs.
“We’re trying to understand the discrepancy,” said Katelin Jabbari, a manager of corporate communications at Google. Jabbari repeatedly asked if we could replicate the initial results, as “none of us here have been able to.”
After further back and forth following subsequent inquiries, Jabbari said, “Sorry, don’t have anything for you.”
Bullshit Detector?
Aside from Google’s proprietary tool, there is no easy way for users to test whether an image contains a SynthID watermark. That makes it difficult in this case to determine whether Google’s system initially detected the presence of a SynthID watermark in an image without one, or if subsequent tests missed a SynthID watermark in an image that actually contains one.
As AI become increasingly pervasive, the industry is trying to put behind its long history of being what researchers call a “bullshit generator.”
Supporters of the technology argue tools that can detect if something is AI will play a critical role establishing the common truth amid the pending flood of media generated or manipulated by AI. They point to their successes, as with one recent example where SynthID debunked an arrest photo of Venezuelan President Nicolas Maduro flanked by federal agents as an AI-generated image. The Google tool said the photo was bullshit.
If AI-detection technology fails to produce consistent responses, though, there’s reason to wonder who will call bullshit on the bullshit detector.
The World Health Organization (WHO) has issued a detailed statement regretting the United States decision to leave the UN agency, and declaring that it will leave both the US and the world less safe as a result.
Thousands of people at higher risk of developing cancer due to inherited faulty genes will be regularly checked and tracked by the NHS thanks to a first-of-its-kind national genetics programme. The world-first genetic register, developed by the NHS, will collect patient information on over 100 genes linked to an increased risk of cancer, with plans […]
We’re taking part in Copyright Week, a series of actions and discussions supporting key principles that should guide copyright policy. Every day this week, various groups are taking on different elements of copyright law and policy, and addressing what’s at stake, and what we need to do to make sure that copyright promotes creativity and innovation.
Long before generative AI, copyright holders warned that new technologies for reading and analyzing information would destroy creativity. Internet search engines, they argued, were infringement machines—tools that copied copyrighted works at scale without permission. As they had with earlier information technologies like the photocopier and the VCR, copyright owners sued.
Courts disagreed. They recognized that copying works in order to understand, index, and locate information is a classic fair use—and a necessary condition for a free and open internet.
Today, the same argument is being recycled against AI. It’s whether copyright owners should be allowed to control how others analyze, reuse, and build on existing works.
Fair Use Protects Analysis—Even When It’s Automated
U.S. courts have long recognized that copying for purposes of analysis, indexing, and learning is a classic fair use. That principle didn’t originate with artificial intelligence. It doesn’t disappear just because the processes are performed by a machine.
Copying that works in order to understand them, extract information from them, or make them searchable is transformative and lawful. That’s why search engines can index the web, libraries can make digital indexes, and researchers can analyze large collections of text and data without negotiating licenses from millions of rightsholders. These uses don’t substitute for the original works; they enable new forms of knowledge and expression.
Training AI models fits squarely within that tradition. An AI system learns by analyzing patterns across many works. The purpose of that copying is not to reproduce or replace the original texts, but to extract statistical relationships that allow the AI system to generate new outputs. That is the hallmark of a transformative use.
Attacking AI training on copyright grounds misunderstands what’s at stake. If copyright law is expanded to require permission for analyzing or learning from existing works, the damage won’t be limited to generative AI tools. It could threaten long-standing practices in machine learning and text-and-data mining that underpin research in science, medicine, and technology.
Researchers already rely on fair use to analyze massive datasets such as scientific literature. Requiring licenses for these uses would often be impractical or impossible, and it would advantage only the largest companies with the money to negotiate blanket deals. Fair use exists to prevent copyright from becoming a barrier to understanding the world. The law has protected learning before. It should continue to do so now, even when that learning is automated.
A Road Forward For AI Training And Fair Use
One court has already shown how these cases should be analyzed. In Bartz v. Anthropic, the court found that using copyrighted works to train an AI model is a highly transformative use. Training is a kind of studying how language works—not about reproducing or supplanting the original books. Any harm to the market for the original works was speculative.
The court in Bartz rejected the idea that an AI model might infringe because, in some abstract sense, its output competes with existing works. While EFF disagrees with other parts of the decision, the court’s ruling on AI training and fair use offers a good approach. Courts should focus on whether training is transformative and non-substitutive, not on fear-based speculation about how a new tool could affect someone’s market share.
AI Can Create Problems, But Expanding Copyright Is the Wrong Fix
Workers’ concerns about automation and displacement are real and should not be ignored. But copyright is the wrong tool to address them. Managing economic transitions and protecting workers during turbulent times may be core functions of government, but copyright law doesn’t help with that task in the slightest. Expanding copyright control over learning and analysis won’t stop new forms of worker automation—it never has. But it will distort copyright law and undermine free expression.
Broad licensing mandates may also do harm by entrenching the current biggest incumbent companies. Only the largest tech firms can afford to negotiate massive licensing deals covering millions of works. Smaller developers, research teams, nonprofits, and open-source projects will all get locked out. Copyright expansion won’t restrain Big Tech—it will give it a new advantage.
Fair Use Still Matters
Learning from prior work is foundational to free expression. Rightsholders cannot be allowed to control it. Courts have rejected that move before, and they should do so again.
Search, indexing, and analysis didn’t destroy creativity. Nor did the photocopier, nor the VCR. They expanded speech, access to knowledge, and participation in culture. Artificial intelligence raises hard new questions, but fair use remains the right starting point for thinking about training.
Ro Khanna is the U.S. representative for California’s 17th Congressional district, more commonly known as “Silicon Valley.” He was a co-chair of Bernie Sanders’ presidential campaign in 2020, and there’s been speculation he may run for president himself in 2028. He joined Current Affairs associate editor Alex Skopic to discuss his bipartisan efforts to release the Epstein files, a “new FDR moment” for the Democratic Party, and the dangerous state of U.S. foreign policy under Donald Trump.
This week, Internet Archive celebrated Public Domain Day with a lively mix of ideas, art, and community. Session recordings are now available to revisit or discover the highlights.
In our daytime virtual session, we invited audiences to step into The Case of the Disappearing Copyright, a playful, thought-provoking celebration of the works newly freed into the public domain. Watch the recording.
Our in-person party turned Public Domain Day into a lively celebration of art, film, and the public domain. Artist in residence Cindy Rehm shared The Seers, her public-domain–inspired work, followed by a screening of the winning films and honorable mentions from the Public Domain Film Remix Contest. Watch the livestream.
SPARC and Curationist represent key collaborative institutions from library world and the museum space, respectively. SPARC is an umbrella advocacy group with more than 250 North American research libraries and academic organizations as its members; Curationist, a digital platform helping museums and archives open their collections to each other and to the world.
Notwithstanding their distinct areas of focus, SPARC and Curationist are dedicated memory institutions, specializing to meet the needs of their patrons, members, and users, but never forgetting their shared goal of preserving culture and providing equal access to knowledge. That is why both are concerned about the effect that outdated laws are having on cultural heritage organizations in the digital age—and why they’ve joined Our Future Memory’s fight to protect memory institutions’ absolutely vital operations, in a media environment where affordable access to trustworthy information is at a premium.
“Curationist is signing this statement because the future of cultural memory depends on the ability of museums, libraries, and archives to operate fully and responsibly in the digital world,” said Executive Director Christian Dawson. “These rights are not abstract ideals. They are the practical foundations that allow institutions to preserve knowledge, provide access, and collaborate across borders. Our work exists to help make these rights real in practice, and we are proud to stand with a global community committed to protecting the past to power the future.”
To be sure, these “practical foundations” should not be controversial. They reflect the historical operations that have made libraries, archives, museums, and other memory institutions such an essential part of our information ecosystem. The Statement calls for legal assurances of memory institutions’ right and ability to:
Collect digital materials
Preserve digital collections
Provide controlled digital access
Cooperate across institutions
Thanks to SPARC and Curationist, the coalition to protect our future memory just got a bit bigger.
Ready to Join?
Your organization can join the movement and sign the Statement by going to the Our Future Memory website.
Want to learn more?
Register and join our informational webinar this Tuesday, January 27: “Protect Our Future Memory: Join the Call for Library Digital Rights.”
On Tuesday, Nathan Yaffe explained how immigration agencies’ are now openly defying federal courts. In more than 1,600 habeas cases, federal judges have ruled that ICE is breaking the law by imposing blanket mandatory detention on people in immigration proceedings. Yet ICE continues to enforce the policy, effectively nullifying judicial oversight through sheer scale. Perhaps most worrisome…
For fans of manga and manhwa comics, Bato.to has been an icon for many years.
The pirate site has reportedly changed owners over the years, but through the main site and dozens of mirrors, it kept its many millions of monthly visitors on board.
Since last November, the site has not been running smoothly, however. Several moderators reported that the site’s operator, Larry, had become unreachable, which resulted in various technical problems.
Batoto Communities Shut Down
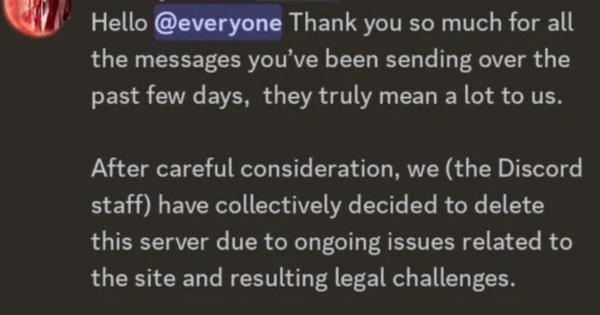
Earlier this week, the trouble appeared to worsen when the official Batoto Discord server, run by the moderation team, announced that it would shut down as well, citing legal challenges and ongoing issues with the site. This effectively confirmed that the site’s moderators were throwing in the towel.
Legal challenges
Not much later, the official Batoto subreddit followed the same route. While it would not shut down completely, the moderators officially cut its ties with anything piracy or Batoto-related.
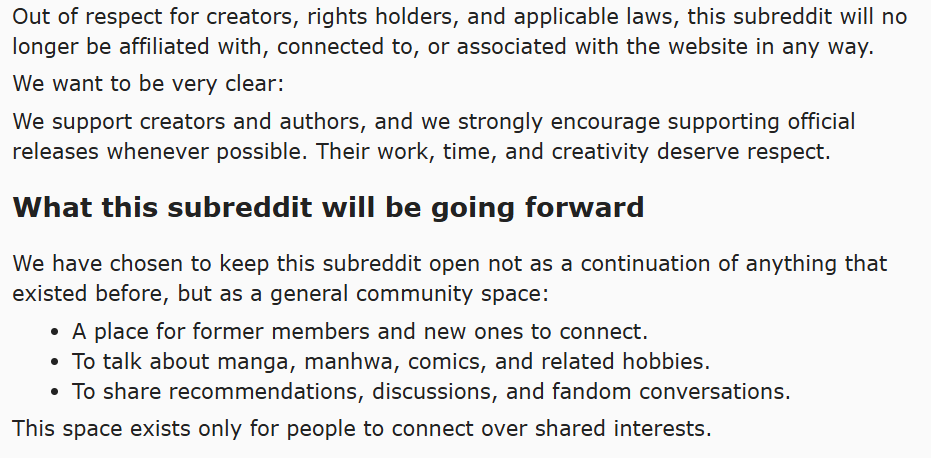
“Due to recent legal developments, it is clear that all activity, discussion, or support related to the former website and its services has permanently ended,” the subreddit mods wrote.
“Out of respect for creators, rights holders, and applicable laws, this subreddit will no longer be affiliated with, connected to, or associated with the website in any way.”
Subreddit Compliance
The seemingly obligatory mention of supporting legal services suggests that this soft shutdown was also the result of legal action. In fact, it appears that Batoto-related people and communication channels are targeted across the board.
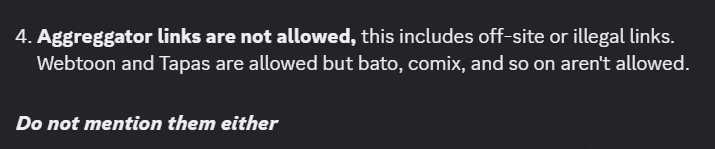
This includes newly launched Discord channels. Only those who abide by a strict set of rules to ban any type of infringement appear to survive. This includes the newly launched Yoru reading community, which specifically prohibits illegal content, pointing people to official Webtoon and Tapas releases instead.
Kakao Entertainment Takes Credit
While it is clear that legal pressure is being applied, the source remained unmentioned. Today we can officially confirm that Kakao Entertainment is driving the action.
Through its dedicated anti-piracy enforcement arm, P.CoK, the South Korean entertainment giant is categorically targeting Bato.to and many related people and services.
The most significant blow to the operation is the identification of Bato.to’s founder and core developer. P.CoK confirmed to TorrentFreak that they have tracked the individual to their country of residence, where legal proceedings are now active.
Responding to this threat, the P.CoK team tackled the problem from multiple sides. In addition to preparing a lawsuit against the operator, it went after other key channels, including the aforementioned communities on Reddit and Discord.
“We adopted a strategy that categorizes individuals involved in the operation into multiple tiers and applies tailored countermeasures to each group. Legal proceedings are currently underway in the country of residence of the founder and core developer,” P.CoK notes.
The P.CoK team
Cease and Desist
The people in lower tiers, including admins and moderators, were also identified. These all received personalized cease-and-desist letters, urging them to shut down their operation, or else.
“We have identified the majority of individuals who are directly or indirectly involved in the operation—such as sub-developers, moderators, and community administrators—and have sequentially issued Cease and Desist (C&D) letters to them,” P.CoK told us.
These cease-and-desist notices came with the relevant legal justification and a specific set of actions these people were expected to take. That likely means showing respect for rightsholders, as we have seen in a few of the public responses.
New Targets?
A final update by the subreddit team confirms the pressure from Kakao Entertainment. Clearly worried that ‘Reddit mods could be next,’ the subreddit was set to restricted.
The subreddit also clearly distances itself from a new Batoto-‘inspired’ site that surfaced online this week.
New?
P.CoK, which has a history of unconventional but effective anti-piracy actions, will undoubtedly keep an eye on any new sites that emerge. At the same time, it is also going after MangaPark and AniXL, which have repeatedly been linked to Batoto. In fact, the anti-piracy group notes that new legal proceedings are already being prepared.
“We are aware that some of these individuals are also involved in the operation of MangaPark and AniXL, and we are preparing strong legal actions against Mangapark as well as newly established Bato-affiliated sites,” P.CoK concludes, suggesting that their work is not done yet.
From: TF, for the latest news on copyright battles, piracy and more.













{kind=link}
{kind=link}